یکی از پر اهمیتترین مباحث در روبرویی با بیماریهای پاندمیک پیشبینی سیر حرکتی بیماری میباشد. این کار با تحلیل و کاوش دادهها امکان پذیر میباشد. در چند ماه اخیر با شیوع بیماری کووید-۱۹ بسیاری از محققین شروع به تحلیل دادههای آماری کردهاند و بسیاری نیز در پی بازنمایی اطلاعات معنیدار استخراج شده از این دادهها هستند. در این نوشته به معرفی مخزن گیتهاب حاوی تعدادی از دادههای موارد ابتلا و نحوه خواندن این دادهها و رسم نمودار لوگاریتمی مبتلایان، بهبودیافتگان و موارد فوتی پرداخته خواهد شد.
بسم الله الرحمن الرحیم
مخزن گیتهابی که برای ذخیرهسازی دادههای آماری مبتلایان به بیماری کووید-۱۹ محیا شده است بهصورت زیر است:
https://github.com/datasets/covid-19
داخل این مخزن گیتهاب در پوشه data چندین فایل csv موجود است که بهطور مرتب و چند ساعت یکبار بهروز میشوند. برای استفاده و دریافت اطلاعات این مخزن گیتهاب اگر با گیت آشنایی ندارید، باید یا کل مخزن را به یکباره دریافت نمایید یا متناسب با کاری که انجام میهید فایلهای مورد نیاز را دانلود کنید. برای دانلود کل مخزن در صفحه نخست بر روی دکمه سبز رنگ clone or download کلیک نموده و دانلود را انتخاب نمایید. برای دریافت تک فایلها نیز فایل مورد نظر را باز کنید (برای مثال کاری که ما انجام خواهیم داد با دادههای انباشته تمامی کشورها میباشد یعنی فایل countries-aggregated.csv) و بر روی raw کلیک کنید. حال که فایل دادهها را دریافت کردیم میرویم سراغ خواندن اطلاعات آن با کتابخانه csv.
کتابخانه csv برای خواندن دادههای ذخیره شده با این فرمت و نوشتن آنها آماده شده است و استفاده از آن بسیار ساده است. در این قسمت به نحوه خواندن یک فایل توسط این کتابخانه پرداخته میشود. فرض می کنیم دنبال نوشتن تابعی هستیم که نام یک کشور را گرفته و دادههای آماری آن را بازگرداند. کد زیر را در نظر بگیرید تا به تحلیل سطر به سطر آن بپردازیم:
def get_data(country):
aggregated_data = []
with open("countries-aggregated.csv", newline="") as csvfile:
datareader = csv.reader(csvfile, delimiter=",", quotechar="|")
for row in datareader:
if row[1] == country and row[2] != "0":
aggregated_data.append(row)
aggregated_data = array(aggregated_data)
return aggregated_data
همانطور که مشاهده میکنید ما یک تابع با ورودی نام کشور داریم. ابتدا لیستی برای ذخیره دادههای مربوط به این کشور تعریف میشود. سپس با باز کردن فایل countries-aggregated.csv به عنوان csvfile، اقدام به ایجاد یک csv reader به نام datareader میکنیم. با توجه به اینکه در هر سطر از داده در فایل مذکور با استفاده از یک «,» اطلاعات از هم جدا شدهاند delimiter را برابر با «,» قرار میدهیم. در فایل مذکور quote بکار نرفته پس quotechar متداول یعنی «|» را استفاده مینماییم. حال با یک حلقه for روی datareader تمامی دادههای فایل را میخوانیم. چک میکنیم اگر نام کشور (یعنی عنصر دوم هر سطر با اندیس ۱) با نامی که داده شده است برابر باشد و تعداد مبتلایان (عنصر سوم هر سطر با اندیس ۲) غیر صفر باشد، داده را به لیست ما اضافه کند.
دقت کنید که هر سطر داده بهصورت زیر میباشد:
۲۰۲۰-۰۴-۰۶,Kyrgyzstan,216,33,4
که به ترتیب تاریخ، نام کشور، تعداد مجموع مبتلایان به کووید-۱۹، تعداد مجموع بهبود یافتگان و تعداد مجموع فوت شدگان را نشان میدهید. همچنین بسیاری از کشورها تا تاریخ مشخصی هنوز گزارش مبتلا نداشتهاند برای همین در شرطی که نوشتیم یک عطف هم به شروع گزارش حداقل یک مورد مبتلا اضافه کردهایم. حال که دادهها را «به شکل متنی» خواندیم با تبدیل آن به آرایه numpy آن را بر میگردانیم.
حال با خواندن دادههای کشور ایران سراغ قسمت رسم نمودارها میرویم. چون رشد تعداد مبتلایان در این بیماری به شکل نمایی است، لذا رسم باید بر روی محور لوگاریتمی و با استفاده از تابع semilogy از pyplot انجام شود. همچنین لازم است قبل از رسم دادهها آنها را به نوع عدد با ممیز شناور تبدیل نماییم که این امر مثلا برای تعداد مبتلایان به شکل زیر محقق میگردد:
iran_aggregated_data[:, 2].astype("float")
که با اینکار برای ستون سوم دادهها و کل سطرها دادهها به نوع ممیز شناور تبدیل میشوند. دقت کنید فراخوانی این تابع نوع دادههای آرایه iran_aggregated_data را تغییر نمیدهد بلکه مقداری که بر میگرداند ستون مورد نظر با نوع داده مورد نظر است. کدهای مورد نیاز برای رسم دادهها نیز به شکل زیر خواهد بود:
plt.figure()
plt.semilogy(iran_aggregated_data[:, 2].astype("float"), label="Total confirmed cases")
plt.semilogy(iran_aggregated_data[:, 3].astype("float"), label="Total number of recoveries")
plt.semilogy(iran_aggregated_data[:, 4].astype("float"), label="Total number of deaths")
plt.xlabel("Days after first case")
plt.ylabel("Cases")
plt.legend()
plt.grid(True)
plt.show()
در نهایت اگر بخواهیم تمام کدها را جمع بندی نموده و به شکل واحد بنویسیم، این چنین خواهد بود:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Jun 7 10:53:16 2020
@author: arslan
"""
from numpy import array
import matplotlib.pyplot as plt
import csv
def get_data(country):
aggregated_data = []
with open("countries-aggregated.csv", newline="") as csvfile:
datareader = csv.reader(csvfile, delimiter=",", quotechar="|")
for row in datareader:
if row[1] == country and row[2] != "0":
aggregated_data.append(row)
aggregated_data = array(aggregated_data)
return aggregated_data
iran_aggregated_data = get_data("Iran")
plt.figure()
plt.semilogy(iran_aggregated_data[:, 2].astype("float"), label="Total confirmed cases")
plt.semilogy(iran_aggregated_data[:, 3].astype("float"), label="Total number of recoveries")
plt.semilogy(iran_aggregated_data[:, 4].astype("float"), label="Total number of deaths")
plt.xlabel("Days after first case")
plt.ylabel("Cases")
plt.legend()
plt.grid(True)
plt.show()
خروجی این کد نیز به شکل زیر خواهد بود: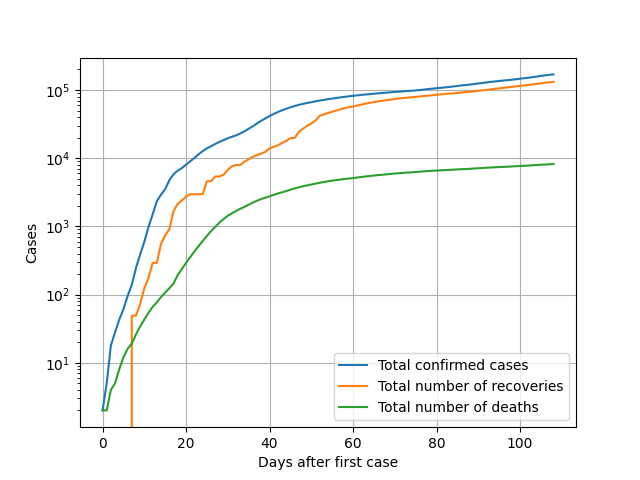
- در نهایت دقت کنید که فایل را به درستی دانلود کرده و در کنار فایل اسکریپت پایتون خود قرار دهید یا آدرس فایل را به درستی بهروزرسانی نمایید.