رگرسیون خطی تخمین یک پارامتر بهصورت تابعی خطی از تعدادی داده دیگر میباشد. در عمل ما به دنبال به دست آوردن یک خط یا در حالت کلی اَبَر صفحه هستیم که با توجه به معیار خطای تعریف شده بهینه است. این روش کاربرد ویژه در علوم و مهندسی داشته و آشنایی با نحوه پیادهسازی آن در پایتون موضوع این نوشته میباشد.
بسم الله الرحمن الرحیم
تئوری این مبحث محل بحث در این مقاله نمیباشد و فرض میگردد خواننده با مباحث ریاضیاتی رگرسیون خطی آشنایی دارد. لذا مستقیم به پیادهسازی روش میپردازیم. ابتدای کار کتابخانههایی که برای نوشتن و پیادهسازی رگرسیون خطی مورد نیاز از فراخوانی مینماییم. کتابخانههای مورد نیاز برای ما numpy برای محاسبات ماتریسی و ریاضی، matplotlib برای بازنمایی دادهها و خروجی رگرسیون و تابع make_regression از کتابخانه scikit-learn برای ایجاد مجموعه دادههای مورد استفاده در این پروژه، میباشند:
import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import make_regression
برای ادامه کار ما یک کلاس تحت عنوان LinearRegression خواهیم ساخت که دارای توابع زیر میباشد:
- fit: این تابع ضرایب مدل ما را از روی دادهها تعیین خواهد نمود.
- predict: با استفاده از این تابع خواهیم توانست خروجی مدل خود را برای ورودیهای دلخواه ارزیابی نماییم.
- rmse: این تابع ریشه میانگین مربعات خطا را توسط یک سری از دادهها برای مدل ساخته شده محاسبه مینماید.
پس ساختار کلی کلاس رگرسور ما به شکل زیر خواهد بود:
class LinearRegression:
def fit(self, X, y, method, learning_rate=0.01, iterations=500, batch_size=32):
return
def predict(self, X):
return
def rmse(self, X, y):
return
برای ادامه کار از تابع fit شروع می کنیم. این تابع وظیفه تعیین ضرایب مدل بر اساس دادههای آموزش را بر عهده دارد. ورودیهای این تابع عبارت اند از:
- دادههای ورودی
- خروجیهای متناظر با دادههای ورودی
- روش یافتن ضرایب
- نرخ یادگیری
- تعداد تکرار
- اندازه دستهها برای انجام یادگیری
در نظر گرفته می شود که این تابع بتواند ضرایب را هم با استفاده از رابطه فرم بسته و هم با استفاده از روش گرادیان نزولی تصادفی تعیین نماید. زمانی که ورودی method تابع fit برابر sgd باشد روش مورد نظر گرادیان نزولی خواهد بود و زمانی که برابر solve باشد از رابطه به فرم بسته استفاده خواهد گردید.
class LinearRegression:
def fit(self, X, y, method, learning_rate=0.01, iterations=500, batch_size=32):
X = np.concatenate([X, np.ones_like(y)], axis=1)
rows, cols = X.shape
if method == 'solve':
pass
elif method == 'sgd':
pass
else:
print(f'Unknown method: \'{method}\'')
return self
حال ببینیم با استفاده از هر کدام از این روشها چگونه میتوانیم ضرایب را تعیین کنیم. زمانی که ما از فرم بسته استفاده می کنیم به این معنی است که می خواهیم معکوس مجازی (یا در شرایط مشخص همان معکوس) یک ماتریس را که بیانگر دسته معادلات خطی است، پیدا کنیم. اینجا ما دو حالت داریم زمانی که تعداد معادلات مستقل بیشتر از یا مساوی با متغیرها می باشد و زمانی که کمتر از متغیرها است. وقتی تعداد معادلات کمتر از متغیرها باشد ما بیشمار پاسخ می توانیم داشته باشیم و باید از روش گرادیان نزولی تصادفی استفاده کنیم. ضرایب مدل با استفاده از معکوس مجازی از رابطه زیر قابل محاسبه میباشد:
![]()
قسمت اول تابع fit به محاسبه ضرایب با رابطه بالا اختصاص دارد که در زیر قابل مشاهده است:
class LinearRegression:
def fit(self, X, y, method, learning_rate=0.01, iterations=500, batch_size=32):
X = np.concatenate([X, np.ones_like(y)], axis=1)
rows, cols = X.shape
if method == 'solve':
if rows >= cols == np.linalg.matrix_rank(X):
self.weights = np.matmul(
np.matmul(
np.linalg.inv(
np.matmul(
X.transpose(),
X)),
X.transpose()),
y)
else:
print('X has not full column rank. method=\'solve\' cannot be used.')
قسمت بعدی که با استفاده از روش گرادیان نزولی تصادفی نوشته خواهد شد دارای شبه کدی مشابه تصویر زیر میباشد:

در این روش همان طور که مشاهده می شود به تعداد تکرارهای تعیین شده دستههایی از داده ها انتخاب میشود و متناسب با خطای موجود با در نظر گرفتن ضرایب و خروجی مطلوب اقدام به بروز رسانی ضرایب می گردد. کد این قسمت نیز به شکل زیر به تابع fit اضافه می گردد:
class LinearRegression:
def fit(self, X, y, method, learning_rate=0.01, iterations=500, batch_size=32):
X = np.concatenate([X, np.ones_like(y)], axis=1)
rows, cols = X.shape
if method == 'solve':
if rows >= cols == np.linalg.matrix_rank(X):
self.weights = np.matmul(
np.matmul(
np.linalg.inv(
np.matmul(
X.transpose(),
X)),
X.transpose()),
y)
else:
print('X has not full column rank. method=\'solve\' cannot be used.')
elif method == 'sgd':
self.weights = np.random.normal(scale=1/cols, size=(cols, 1))
for i in range(iterations):
Xy = np.concatenate([X, y], axis=1)
np.random.shuffle(Xy)
X, y = Xy[:, :-1], Xy[:, -1:]
for j in range(int(np.ceil(rows/batch_size))):
start, end = batch_size*j, np.min([batch_size*(j+1), rows])
Xb, yb = X[start:end], y[start:end]
gradient = 2*np.matmul(
Xb.transpose(),
(np.matmul(Xb,
self.weights)
- yb))
self.weights -= learning_rate*gradient
else:
print(f'Unknown method: \'{method}\'')
return self
در ادامه نوبت به نوشتن توابع predict و rmse میرسد. ابتدا سراغ تابع predict میرویم:
def predict(self, X):
if not hasattr(self, 'weights'):
print('Cannot predict. You should call the .fit() method first.')
return
X = np.concatenate([X, np.ones((X.shape[0], 1))], axis=1)
if X.shape[1] != self.weights.shape[0]:
print(f'Shapes do not match. {X.shape[1]} != {self.weights.shape[0]}')
return
return np.matmul(X, self.weights)
این تابع که تنها ورودی آن دستهای از دادهها میباشد، ابتدا از مقداردهی شدن ضرایب وزنی مطمئن میشود. در صورتی که کلاس فاقد عنصر weights باشد به کاربر اعلام میکند که باید ابتدا با استفاده از تعدادی داده ورودی اقدام به فراخوانی تابع fit برای تعیین وزنهای رگرسور نماید. بعد از آن با استفاده از X و بردار تماما یک اقدام به تشکیل ماتریس افزوده مینماید که مورد نیاز برای محاسبات است. سپس تابع، تطابق ابعاد بردار وزنها را با ماتریس X ارزیابی مینماید تا در صورت عدم تطابق کاربر را مطلع کرده و ادامه کار را متوقف نماید. در نهایت حاصل ضرب ماتریس X و بردار وزنها را که خروجی رگرسور میباشد، باز میگرداند. تنها تابع باقیمانده برای بررسی، تابع خطا یعنی rmse میباشد که به شکل زیر است:
def rmse(self, X, y):
y_hat = self.predict(X)
if y_hat is None:
return
return np.sqrt(((y_hat - y)**2).mean())
در این تابع ابتدا خروجیهای رگرسور به ازای ورودی داده شده ارزیابی میگردند. سپس اگر خروجی با موفقیت بازگردانده شده باشد، ریشه میانگین مربعات خطای خروجی حاصل نسبت به خروجی مطلوب محاسبه شده و بازگردانده میشود. حال بیابید تمام کدهای نوشته شده را در یک مثال به کار ببریم. برای استفاده از کلاس رگرسور خطی نوشته شده ورودیها و خروجیهای آزمایشی با استفاده از تابع make_regression از کتابخانه sklearn ایجاد و رسم میگردند.
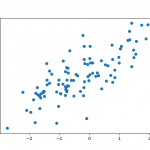
X, y = make_regression(n_features=1,
n_informative=1,
bias=1, noise=35)
plt.figure()
plt.scatter(X, y)
در ادامه بعد از اعمال تغییرات مناسب برای سازگار شدن ابعاد بردار پاسخ، شیی از نوع LinearRegression و یافتن ضرایب با روش به فرم بسته ساخته میشود:
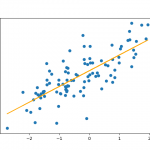
y = y.reshape((-1, 1)) lr_solve = LinearRegression().fit(X, y, method='solve')
در ادامه خروجی رگرسور برای ورودیها محاسبه و رسم میگردند و خطای رکرسیون در خروجی چاپ میگردد:
plt.figure() plt.scatter(X, y) plt.plot(X, lr_solve.predict(X), color='orange') print(lr_solve.rmse(X, y))
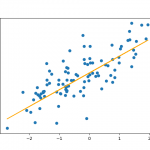
همچنین بطور مشابه شی LinearRegression دوباره ایجاد میگردد، با این تفاوت که این بار روش یافتن ضرایب رگرسور گرادیان نزولی تصادفی میباشد:
lr_sgd = LinearRegression().fit(X, y, method='sgd')
باز بطور مشابه خروجیهای حاصل از این رگرسور محاسبه و رسم میگردند و خطای رگرسیون نیز در خروجی چاپ میشود:
plt.figure() plt.scatter(X, y) plt.plot(X, lr_sgd.predict(X), color='orange') print(lr_sgd.rmse(X, y))
در نهایت میتوان تمام کدهای نوشته شده را به شکل زیر جمع بندی نمود:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Wed Sep 2 20:35:05 2020
@author: arslan
"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_regression
class LinearRegression:
def fit(self, X, y, method, learning_rate=0.01, iterations=500, batch_size=32):
X = np.concatenate([X, np.ones_like(y)], axis=1)
rows, cols = X.shape
if method == 'solve':
if rows >= cols == np.linalg.matrix_rank(X):
self.weights = np.matmul(
np.matmul(
np.linalg.inv(
np.matmul(
X.transpose(),
X)),
X.transpose()),
y)
else:
print('X has not full column rank. method=\'solve\' cannot be used.')
elif method == 'sgd':
self.weights = np.random.normal(scale=1/cols, size=(cols, 1))
for i in range(iterations):
Xy = np.concatenate([X, y], axis=1)
np.random.shuffle(Xy)
X, y = Xy[:, :-1], Xy[:, -1:]
for j in range(int(np.ceil(rows/batch_size))):
start, end = batch_size*j, np.min([batch_size*(j+1), rows])
Xb, yb = X[start:end], y[start:end]
gradient = 2*np.matmul(
Xb.transpose(),
(np.matmul(Xb,
self.weights)
- yb))
self.weights -= learning_rate*gradient
else:
print(f'Unknown method: \'{method}\'')
return self
def predict(self, X):
if not hasattr(self, 'weights'):
print('Cannot predict. You should call the .fit() method first.')
return
X = np.concatenate([X, np.ones((X.shape[0], 1))], axis=1)
if X.shape[1] != self.weights.shape[0]:
print(f'Shapes do not match. {X.shape[1]} != {self.weights.shape[0]}')
return
return np.matmul(X, self.weights)
def rmse(self, X, y):
y_hat = self.predict(X)
if y_hat is None:
return
return np.sqrt(((y_hat - y)**2).mean())
X, y = make_regression(n_features=1,
n_informative=1,
bias=1, noise=35)
plt.figure()
plt.scatter(X, y)
y = y.reshape((-1, 1))
lr_solve = LinearRegression().fit(X, y, method='solve')
plt.figure()
plt.scatter(X, y)
plt.plot(X, lr_solve.predict(X), color='orange')
print(lr_solve.rmse(X, y))
lr_sgd = LinearRegression().fit(X, y, method='sgd')
plt.figure()
plt.scatter(X, y)
plt.plot(X, lr_sgd.predict(X), color='orange')
print(lr_sgd.rmse(X, y))
نمودارهای خروجی نیز به شکل زیر خواهند بود: